

Run this notebook yourself!
Download the executed notebook: 5_glm.ipynb! See the button at the top right to download as markdown or pdf.
Generalized Linear Model (with NeMoS)#
The NeMoS package, developed by the same team as plenoptic, provides a framework for fitting statistical models for systems neuroscience, including the Generalized Linear Model (GLM). Let’s use nemos to fit a model and then plenoptic to synthesize some metamers!
Because nemos relies on jax, while plenoptic relies on pytorch, we cannot use nemos models with plenoptic directly. Instead, we will:
Fit a GLM model to data, using nemos.
Implement a small GLM in plenoptic
Synthesize some metamers
# needed for the plotting/animating:
import matplotlib.pyplot as plt
import matplotlib as mpl
import plenoptic as po
import torch
import pynapple as nap
import nemos as nmo
import numpy as np
from scipy.io import loadmat
import copy
import jax
jax.config.update("jax_enable_x64", True)
plt.rcParams["animation.html"] = "html5"
# use single-threaded ffmpeg for animation writer
plt.rcParams["animation.writer"] = "ffmpeg"
plt.rcParams["animation.ffmpeg_args"] = ["-threads", "1"]
# so that relative sizes of axes created by po.plot.imshow and others look right
plt.rcParams["figure.dpi"] = 72
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
Fit the GLM with nemos#
In this section, we are doing the same model fit as this tutorial, skipping over much of the explanation. If you are interested in learning more about nemos and/or the GLM, you’re encouraged to work through those tutorials!
This dataset consists of retinal ganglion cells receiving a one-dimensional input: binary temporal white noise (data from Uzzell & Chichilnisky, 2004; see README.txt for details). Here, we will build a GLM that predicts a single neuron’s firing rate as the result of a linear filter convolved with this input.
This first hidden cell defines the function that we’ll use to download the data.
Download and prepare the data, using pynapple, another package developed at Flatiron CCN:
data_paths = fetch_data("data_RGCs")
# Load and wrap spike times
spike_times = loadmat(data_paths["SpTimes.mat"], simplify_cells=True)["SpTimes"]
units = nap.TsGroup({i: nap.Ts(val) for i, val in enumerate(spike_times)})
# Load and wrap stimulus
stim_times = loadmat(data_paths["stimtimes.mat"], simplify_cells=True)["stimtimes"]
stim = loadmat(data_paths["Stim.mat"], simplify_cells=True)["Stim"]
stimulus = nap.Tsd(stim_times, stim)
# Align, count, resample
units = units.restrict(stimulus.time_support)
bin_size = stimulus.t[1] - stimulus.t[0]
counts = units.count(bin_size, stimulus.time_support)
stimulus = counts.value_from(stimulus, mode="before")
cell_idx = 2
neuron_counts = counts[:, cell_idx]
Downloading file 'SpTimes.mat' from 'https://raw.githubusercontent.com/pillowlab/GLMspiketraintutorial_python/main/data_RGCs/SpTimes.mat' to '/home/jenkins/agent/workspace/eurorse_plenoptic-workshops_main/.cache/nemos_tutorials'.
Downloading file 'stimtimes.mat' from 'https://raw.githubusercontent.com/pillowlab/GLMspiketraintutorial_python/main/data_RGCs/stimtimes.mat' to '/home/jenkins/agent/workspace/eurorse_plenoptic-workshops_main/.cache/nemos_tutorials'.
Downloading file 'Stim.mat' from 'https://raw.githubusercontent.com/pillowlab/GLMspiketraintutorial_python/main/data_RGCs/Stim.mat' to '/home/jenkins/agent/workspace/eurorse_plenoptic-workshops_main/.cache/nemos_tutorials'.
The nemos tutorial shows how to split the data into test and train sets. We’re not going to do that here, instead training on the whole data set.
Below we create the basis object that will construct our filter, fit the model, and save the parameters. We also save our stimulus.
basis_stim = nmo.basis.HistoryConv(20, label="stim", conv_kwargs={"shift": False})
X_stim = basis_stim.compute_features(stimulus)
glm_stim = nmo.glm.GLM(observation_model="Poisson")
glm_stim.fit(X_stim, neuron_counts)
glm_stim.save_params("nemos_glm.npz")
np.savez("nemos_stimulus.npz", allow_pickle=False, stimulus=stimulus)
An NVIDIA GPU may be present on this machine, but a CUDA-enabled jaxlib is not installed. Falling back to cpu.
/home/jenkins/agent/workspace/eurorse_plenoptic-workshops_main/.venv/lib/python3.12/site-packages/pynapple/core/utils.py:198: UserWarning: Converting 'd' to numpy.array. The provided array was of type 'ArrayImpl'.
warnings.warn(
Synthesizing GLM metamers with plenoptic#
Building a GLM in plenoptic#
Plenoptic doesn’t currently include a GLM model, though it is in our roadmap (see issue 243 if you’re interested). So here, we will implement a basic GLM that can load in the parameter file we saved above and then use it to synthesize metamers for this simple 1d stimulus.
First, let’s define some helper functions for converting jax arrays to torch tensors and which we’ll use for plotting our metamer. We hide this cell because the details are not that important:
Next, let’s define our GLM model. Note that this class will not work for all nemos GLMs. Currently, only those that use either no basis or nemos.basis.HistoryConv (like the above).
class GLM(torch.nn.Module):
def __init__(self, weight_shape=None, weight=None, bias=None, link_func="exp"):
"""Initialize GLM.
Exactly one of weight or weight_shape must be set. If weight_shape
is set, we randomly initialize the weights in the corresponding shape. Else, we
use the specified weights.
Supports weight_shape (and weight shape) of 1 through 3 dimensions
(inclusive), though this has only been tested with 1d weights.
"""
super().__init__()
if weight_shape is not None and weight is not None:
raise ValueError("Exactly one of weight_shape and weight must be set!")
if weight_shape is None and weight is None:
raise ValueError("Exactly one of weight_shape and weight must be set!")
if weight_shape is None:
weight_shape = weight.shape
dtype = weight.dtype
else:
dtype = torch.float32
if len(weight_shape) == 1:
self.conv = torch.nn.Conv1d(1, 1, weight_shape, dtype=dtype)
elif len(weight_shape) == 2:
self.conv = torch.nn.Conv2d(1, 1, weight_shape, dtype=dtype)
elif len(weight_shape) == 3:
self.conv = torch.nn.Conv3d(1, 1, weight_shape, dtype=dtype)
state_dict = {}
if weight is not None:
state_dict["conv.weight"] = weight.unsqueeze(0).unsqueeze(0)
if bias is not None:
state_dict["conv.bias"] = bias
if link_func == "jax.numpy.exp":
self.link_func = torch.exp
else:
raise ValueError(f"Don't know how to handle {link_func=}")
self.load_state_dict(state_dict)
def forward(self, x, **kwargs):
"""Return predicted firing rate."""
return self.link_func(self.conv(x, **kwargs))
@classmethod
def load_nemos_glm(cls, path):
"""Load the output of nemos GLM's save_params method."""
coeffs_npz = np.load(path)
try:
# this is a simple GLM. we reverse the filter because nemos convention is
# reverse of torch's with respect to time
weight = jax_to_torch(coeffs_npz["item::strkey:coef_"][::-1])
except KeyError:
# this is a GLM that was fit using a pytree, specifying the stimulus filter
weight = jax_to_torch(coeffs_npz["dict::strkey:coef_::item::strkey:stim"][::-1])
bias = jax_to_torch(coeffs_npz["item::strkey:intercept_"])
link_func = coeffs_npz["item::strkey:inverse_link_function"]
return cls(weight=weight, bias=bias, link_func=link_func)
Now, let’s initialize our model using the parameters saved above, switching the model to evaluation mode and removing gradient on its parameters, as is standard in plenoptic.
glm = GLM.load_nemos_glm("nemos_glm.npz")
glm.eval()
po.remove_grad(glm)
Now, load in the stimulus saved above and convert to a torch tensor. We’ll only use the first 200 time points, for simplicity.
stim = jax_to_torch(np.load("nemos_stimulus.npz")["stimulus"], 2)[..., :200]
Now, let’s visualize our model and its predictions:
plot_model(glm, stim);
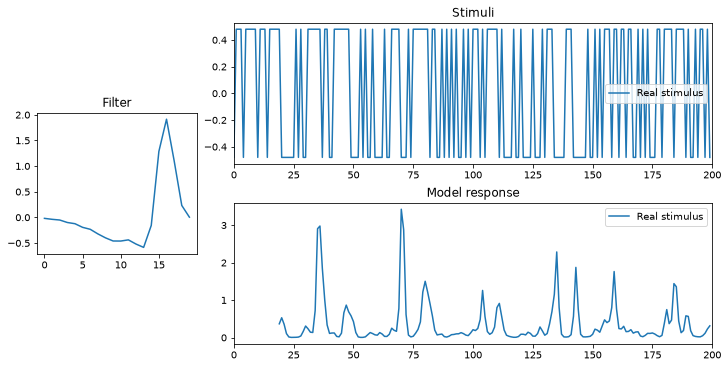
The leftmost plot shows the 1d filter of this model.
The top plot shows the stimulus, the one-dimensional binary noise.
The bottom shows the model’s predicted firing rate, in spikes per second.
Synthesizing metamers#
Synthesize the metamer. In this setup, our only goal is to find a stimulus that gives rise to the same predicted firing rate, with no constraints.
Seed
Note that we set the seed at the top: it is possible for this problem to hit some NaNs during optimization. With seed 1, we reliably find a good solution.
po.set_seed(1)
met = po.Metamer(stim, glm, penalty_lambda=0)
met.setup(optimizer=torch.optim.LBFGS)
met.synthesize(1000, stop_criterion=1e-20)
plot_met(met, "No penalty");
/home/jenkins/agent/workspace/eurorse_plenoptic-workshops_main/.venv/lib/python3.12/site-packages/plenoptic/validate.py:101: UserWarning: plenoptic's methods have mostly been tested on 4d inputs with shape torch.Size([n_batch, n_channels, im_height, im_width]). They should theoretically work with different dimensionality; if you have any problems, please open an issue at https://github.com/plenoptic-org/plenoptic/issues/new?template=bug_report.md
warnings.warn(
/home/jenkins/agent/workspace/eurorse_plenoptic-workshops_main/.venv/lib/python3.12/site-packages/plenoptic/validate.py:116: UserWarning: input_tensor range is (-0.48, 0.48); plenoptic's methods have largely been tested with the range [0, 1]. Synthesis should still work, but if you have any problems, please open an issue.
warnings.warn(
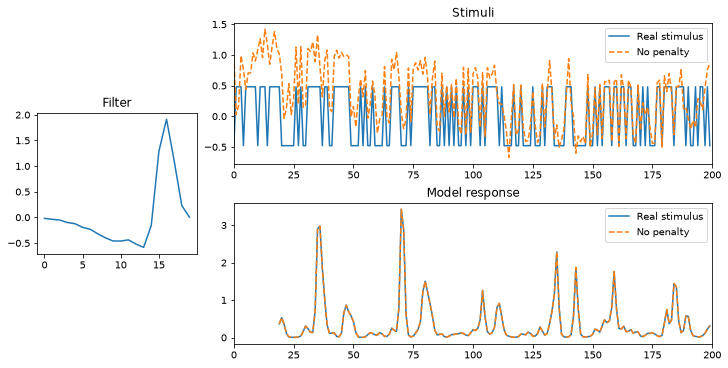
From the bottom subplot, we can see that our metamer is doing a good job: the predicted responses lie directly on top of each other. From the top, we can see that our metamer looks really different from our actual stimulus. In particular, its values are outside the range of our actual stimulus, varying from -0.6 or so up to almost 1.5.
While this may be interesting (our model expects the cell to give similar firing rates to a wider range of stimuli than those tested), in many cases the range of your stimulus is fixed based on the properties of your setup (e.g., you cannot display pixel values outside of some range). In the next section we show how to add a penalty to constrain the range.
Using penalties to find constrain metamer synthesis#
As discussed above, we would like to find a metamer whose values lie within the range of our original stimulus, -0.5 and 0.5. To do so, plenoptic allows you to specify a Regularization penalty, which modifies the objective function.
Constrain range#
The most common way of using penalty_function is to constrain the range. By default, plenoptic constrains the range to lie between 0 and 1. This is reasonable for image pixels (the most common plenoptic use-case), but not our stimulus here. Instead, we’d like the range to vary between -0.5 and 0.5
We can do this using plenoptic.regularize.penalize_range(), specifying the allowed_range value to (-0.5, 0.5):
range_penalty = lambda x: po.regularize.penalize_range(x, (-0.5, 0.5))
range_penalty is now a function that accepts a single tensor and returns a scalar, quadratic penalty on any values it contains outside of -0.5 and 0.5:
# all ones -- high penalty
print(range_penalty(torch.ones(10)))
# all zeros -- no penalty
print(range_penalty(torch.zeros(10)))
# random values between 0 and 1 -- medium penalty
print(range_penalty(torch.rand(10)))
tensor(2.5000)
tensor(0.)
tensor(0.7446)
Now we pass this function to Metamer at initialization and run synthesis as before:
met = po.Metamer(stim, glm, penalty_function=range_penalty)
met.setup(optimizer=torch.optim.LBFGS)
met.synthesize(1000, stop_criterion=1e-20)
plot_met(met, "Range Penalty");
/home/jenkins/agent/workspace/eurorse_plenoptic-workshops_main/.venv/lib/python3.12/site-packages/plenoptic/validate.py:101: UserWarning: plenoptic's methods have mostly been tested on 4d inputs with shape torch.Size([n_batch, n_channels, im_height, im_width]). They should theoretically work with different dimensionality; if you have any problems, please open an issue at https://github.com/plenoptic-org/plenoptic/issues/new?template=bug_report.md
warnings.warn(
/home/jenkins/agent/workspace/eurorse_plenoptic-workshops_main/.venv/lib/python3.12/site-packages/plenoptic/validate.py:116: UserWarning: input_tensor range is (-0.48, 0.48); plenoptic's methods have largely been tested with the range [0, 1]. Synthesis should still work, but if you have any problems, please open an issue.
warnings.warn(
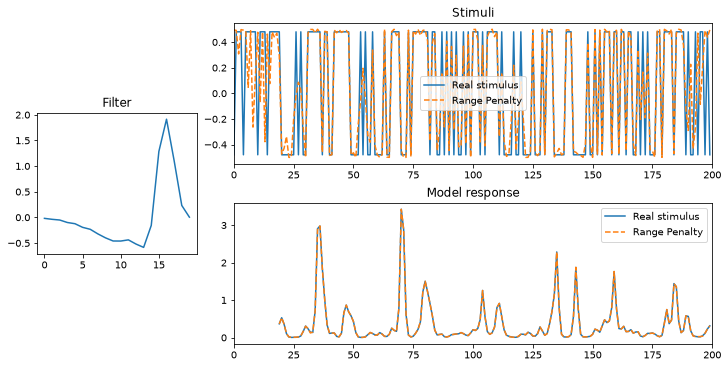
We can see that our resulting metamer is still a good one, with the predicted firing rates lying on top of each other again. However, our new metamer’s values lie between -0.5 and 0.5, as desired. It’s not identical to our original stimulus, but it’s pretty similar. Is that necessarily the case though? What if we tried to find a metamer that was really different from our original stimulus?
Uncorrelated#
We can do that by using a different penalty, one which encourages the metamer to be uncorrelated with the original stimulus:
# this remaps so that the function's minimum value is at target, at which point remap
# returns 0. this works as long as we have a finite target (if our target was -inf, it
# wouldn't)
def remap(x, target=0):
return (x-target).pow(2)
# note that this function accepts a metamer tensor and then correlates it with stim,
# which is defined earlier in this notebook -- it's not an argument to the function
def corr_penalty(metamer, target=0):
# compute pearson R
penalty = torch.corrcoef(torch.stack([stim.squeeze(), metamer.squeeze()], 0))[0, 1]
return remap(penalty, target)
uncorr_penalty = lambda x: corr_penalty(x, 0) + po.regularize.penalize_range(x, (-.5, .5))
This function is slightly more complicated to the above. It accepts a single tensor and returns a scalar which is the sum of this “uncorrelated penalty” and the range penalty. So a tensor with a really low penalty value will be both uncorrelated with our original stimulus and have all values between -0.5 and 0.5.
We can pass this function to Metamer at initialization and run synthesis as before:
met = po.Metamer(stim, glm, penalty_function=uncorr_penalty)
met.setup(optimizer=torch.optim.LBFGS)
met.synthesize(1000, stop_criterion=1e-20)
plot_met(met, "UnCorr+Range Penalty");
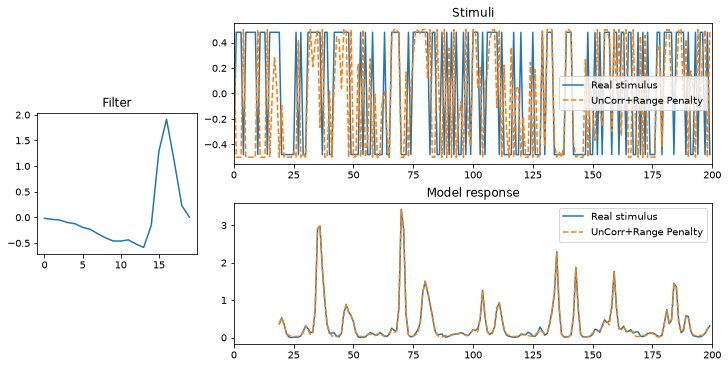
We end up with a metamer that’s quite different from our original stimulus! We can see that our new metamer aligns with the original stimulus for most sustained values (either negative or positive, e.g., around 77 seconds and 140). However, it has the opposite value near rapid transitions (e.g., around 90 seconds)! This highlights that our model is responding to rapid transitions between values, but doesn’t care whether they’re negative-to-positive or the reverse.
Try other penalties!#
What other penalties can you try? They need to accept a single tensor and return a single scalar. Try writing your own!
Plenoptic includes the plenoptic.validate.validate_penalty() function, which can validate your penalty function. If you call it on your function and the code runs without any errors, then you can use your function for metamer synthesis:
penalty_func = # WRITE SOMETHING HERE
po.validate.validate_penalty(penalty_func, stim.shape, stim.dtype)
Try changing the weights of the GLM#
In the above examples, we load in a weights file to set the GLM weights. But you can also specify it yourself! Try initializing the weights to some other tensor and use it to initialize the GLM class, and see what metamers result:
weights = torch.tensor() # WRITE SOMETHING HERE
glm = GLM(weight=weight, bias=) # PICK A BIAS
Try making it multi-dimensional#
So far, we’ve only looked at 1d GLMs. But you could build a 2d or even a 3d one, just make weight the appropriate shape! Of course, you’ll also need a stimulus of the appropriate dimensionality as well.
Plenoptic includes some LGN-inspired models you can raid for their spatial filter, and then combine them a temporal filter to build a 3d GLM.
model = po.models.CenterSurround(kernel_size=10, on_center=True)
# grab 2d center-surround filter
filt = model.filt.squeeze()
print(filt.shape)
torch.Size([10, 10])